Proteins are macromolecules. They are constructed from one or more unbranched chains of amino acids; that is, they are polymers. An average eukaryotic protein contains around 500 amino acids but some are much smaller (the smallest are often called peptides) and some much larger (the largest to date is titin a protein found in skeletal and cardiac muscle; one version contains 34,350 amino acids in a single chain!).
| Link to a discussion of how the amino acids are linked together. |
Every function in the living cell depends on proteins.
The protein represented here displays many of the features of proteins. Let's examine some of them as you scroll down the image.

The protein consists of two polypeptide chains, a long one on the left of 346 amino acids — it is called the heavy chain — and a short one on the right of 99 amino acids.
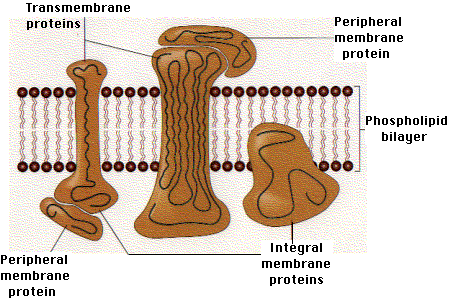
The heavy chain is shown as consisting of 5 main regions or domains:Because it is anchored in the plasma membrane of the cell, the heavy chain is called an integral membrane protein.
To the right is the protein molecule called beta-2 microglobulin. It is not attached to the heavy chain by any covalent bonds, but rather by a number of noncovalent interactions like hydrogen bonds. Proteins associated noncovalently with integral membrane proteins are called peripheral membrane proteins.
| Link to a color diagram showing the relationship between integral and peripheral membrane proteins (48K) |
The dark bars represent disulfide (S—S) bridges linking portions of each external domain (except the N domain). However, the bonds in S—S bridges are no longer than any other covalent bond, so if this molecule could be viewed in its actual tertiary (3D) configuration, we would find that the portions of the polypeptide chains containing the linked Cys are actually close together.
| Link to a color model showing this (92K). But note that the terminology for the domains is different in this model: N = alpha1, C1 = alpha2, C2 = alpha 3 |
The two objects on the left of the image that look like candelabra represent short, branched chains of sugars. The base of each is attached to an asparagine (N). Proteins with covalently linked carbohydrate are called glycoproteins. When the carbohydrate is linked to asparagine, it is said to be "N-linked".
The presence of sugars on the molecule makes this region hydrophilic as befits its location projecting into the fluid that surrounds the cell. The amino acids exposed at the surface of the extracellular domains tend to be hydrophilic as well.
However, most of the amino acids in the transmembrane domain are hydrophobic, as befits their hydrophobic surroundings.
Most of the amino acids in the cytoplasmic domain are hydrophilic, which is appropriate for the aqueous medium of the cytosol, but carbohydrate is not found in the intracellular domains of integral membrane proteins.
The regions marked "Papain" represent the places on the long chain that are attacked by the proteinase papain (and made it possible to release the extracellular domains from the plasma membrane for easier analysis).
This molecule represents a "single-pass" transmembrane protein; the polypeptide chain traverses the plasma membrane once only. However, many transmembrane proteins pass through several, but always a precisely defined number, of times [Example].
This image (courtesy of T.J. Kindt and J. E. Coligan) represents the structure of a class I histocompatibility molecule, called H-2K. Almost all the cells of an animal's body (in this case, a mouse) have thousands of these molecules present in their plasma membrane. These molecules provide tissue identity and serve as major targets in the rejection of transplanted tissue and organs. Hence molecules of this type are often called transplantation antigens. But tissue rejection is not their natural function. Class I molecules serve to display antigens on the surface of the cell so that they can be "recognized" by T cells.
| Discussion of antigen presentation by class I molecules |
When proteins are first synthesized, a process called translation, they consist of a linear assembly of the various amino acids, of which only 20 are normally used.
| Translation: How proteins are synthesized using the genetic code. |
Some bacteria, plants, and animals (but not humans) cut one or more peptides out of certain of their translated proteins and link the free ends together to form a circular protein. The details of how this is done are not yet known, but with a free amino group at one end and a free carboxyl at the other (the groups that form all peptide bonds), there is no chemical difficulty to overcome. The advantage of circular proteins seems to be great resistance to degradation (e.g., no free end for peptidases to work on).
Another, very rare, post-translational modification is the later removal of a section of the polypeptide and the splicing together (with a peptide bond) of the remaining N-terminal and C-terminal segments. The portion removed is called an intein (a "protein intron"), and the ligated segments are called exteins ("protein exons").
Genes encoding inteins have been discovered in a variety of organisms, including| How Proteins Get Their Shape |
| Primary Structure |
| Secondary Structure |
| Tertiary Structure |
| Quaternary Structure |
| How proteins are delivered to their proper destination in the cell. |
| Welcome&Next Search |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}